Proprietary Diligence Technology · Holding Advisory LLC
CortexDD
Due Diligence
Engine
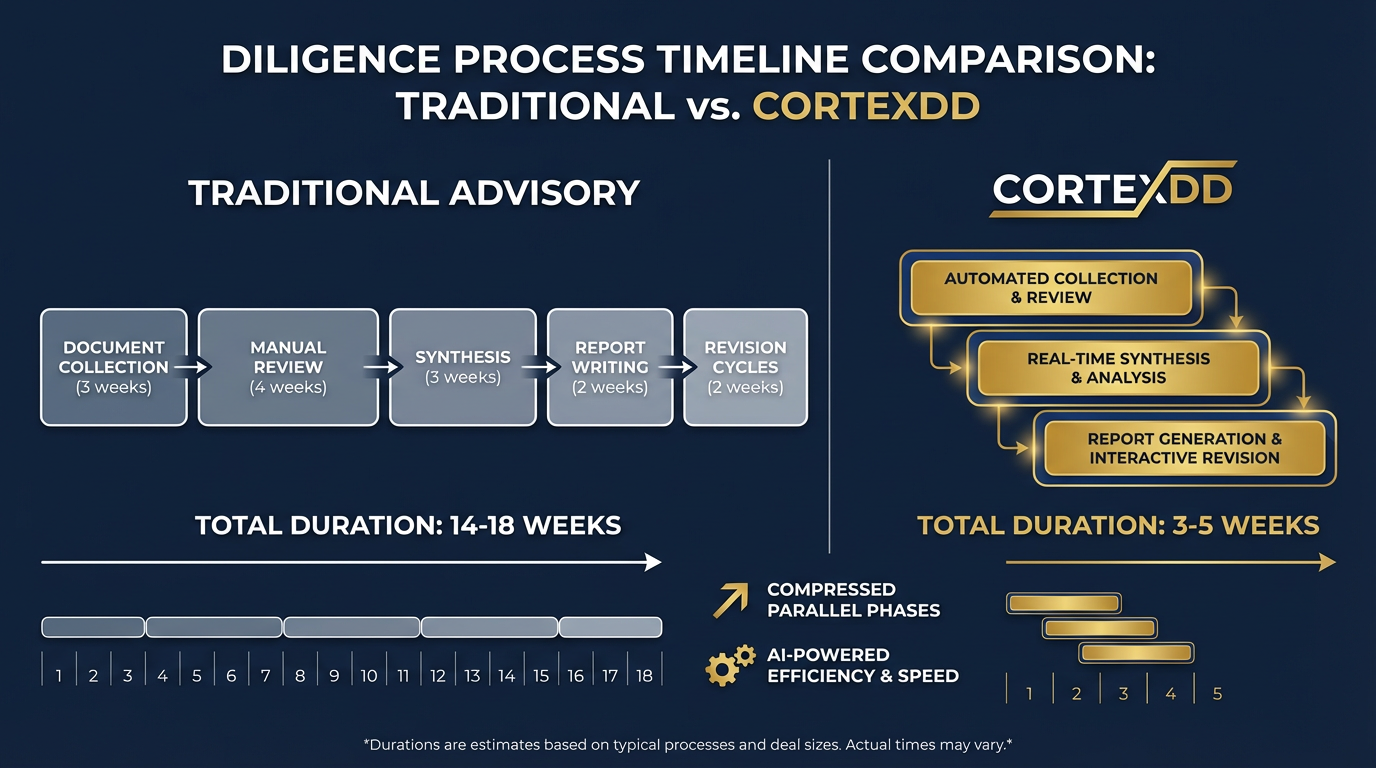
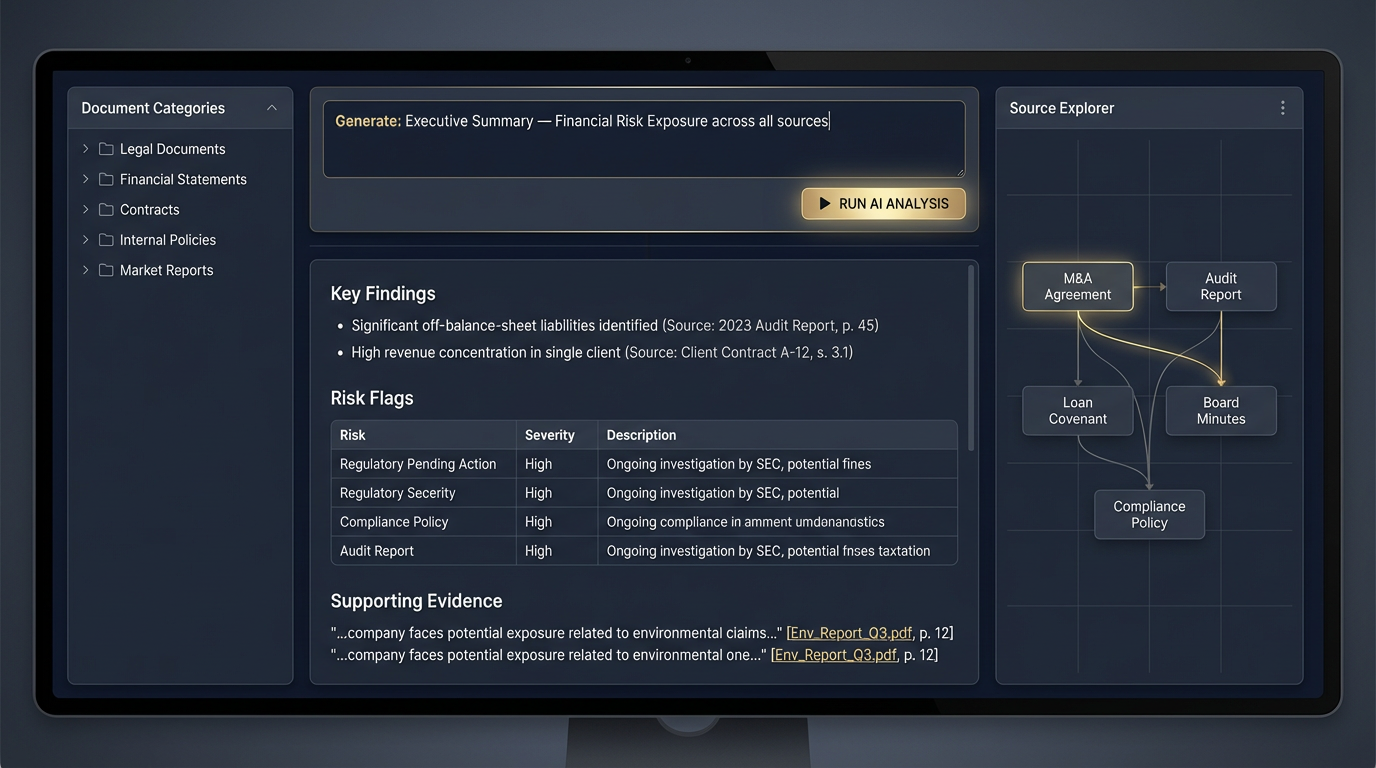
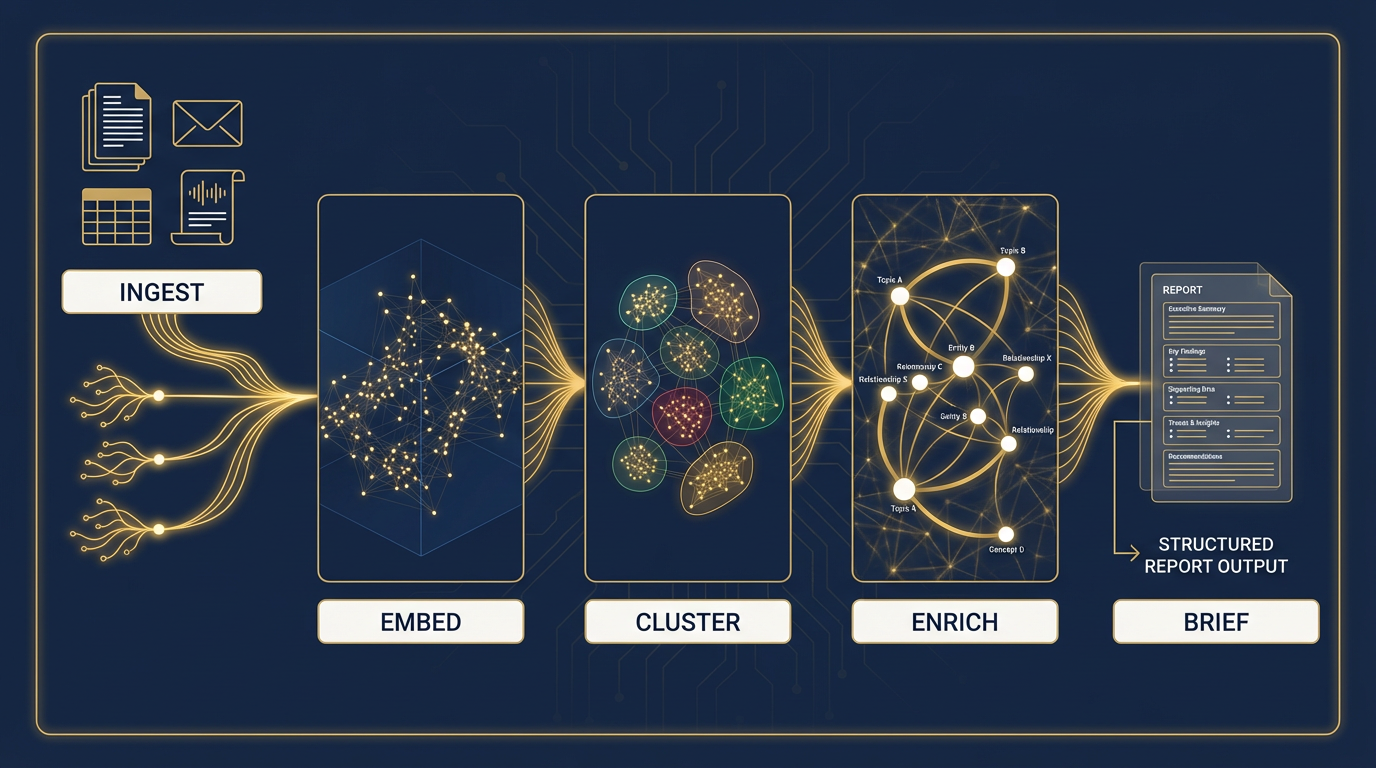
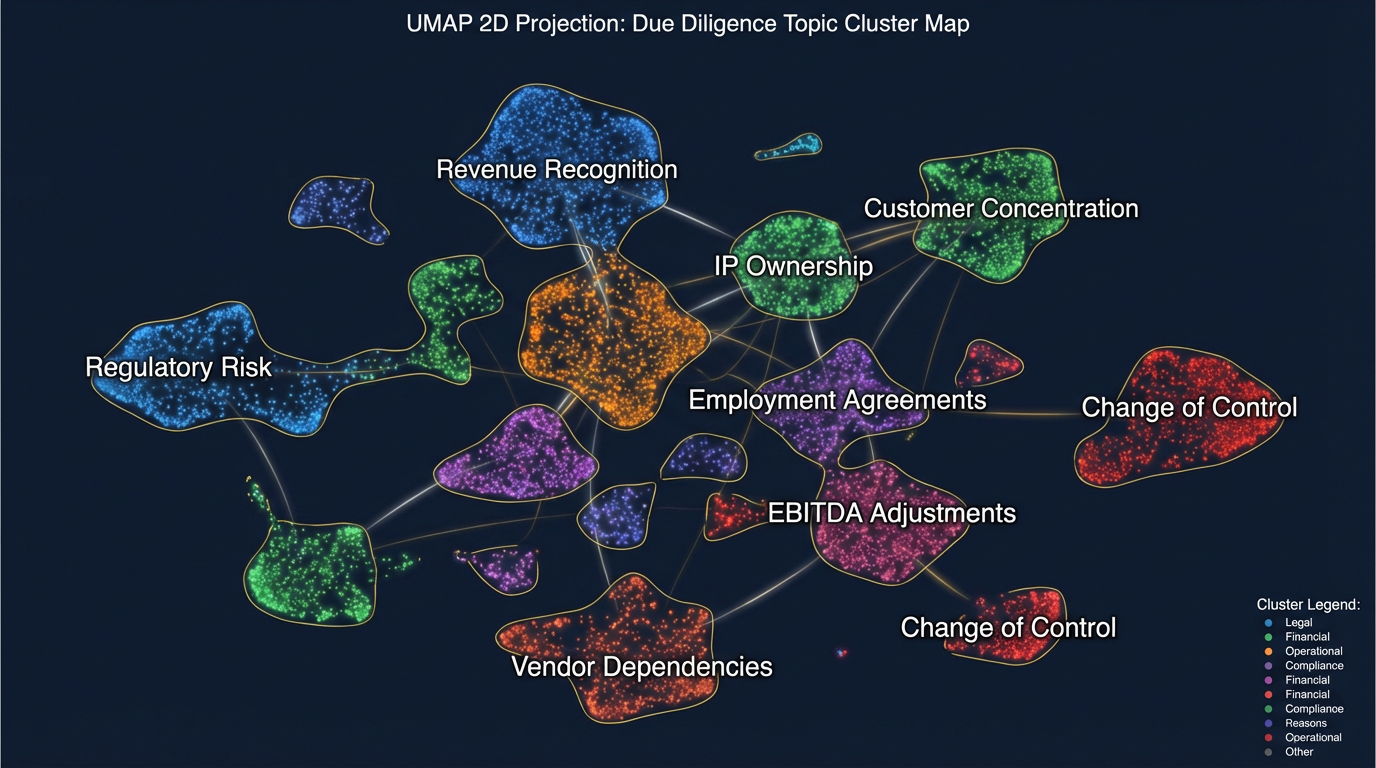
A proprietary engine that goes beyond the data room. CortexDD connects directly to a target's financial systems, CRM, email, HR platforms, and operational tools — pulling diligence-critical information at the source. The result: a smaller data room burden on the target, deeper coverage for the buyer, and structured diligence briefs backed by source evidence — produced in days, not months.
Data Room + Live Systems
Direct ERP · CRM · Email Access
Cross-Source Analysis
Hidden Risk Discovery
Contradiction Detection
Evidence-Backed Briefs
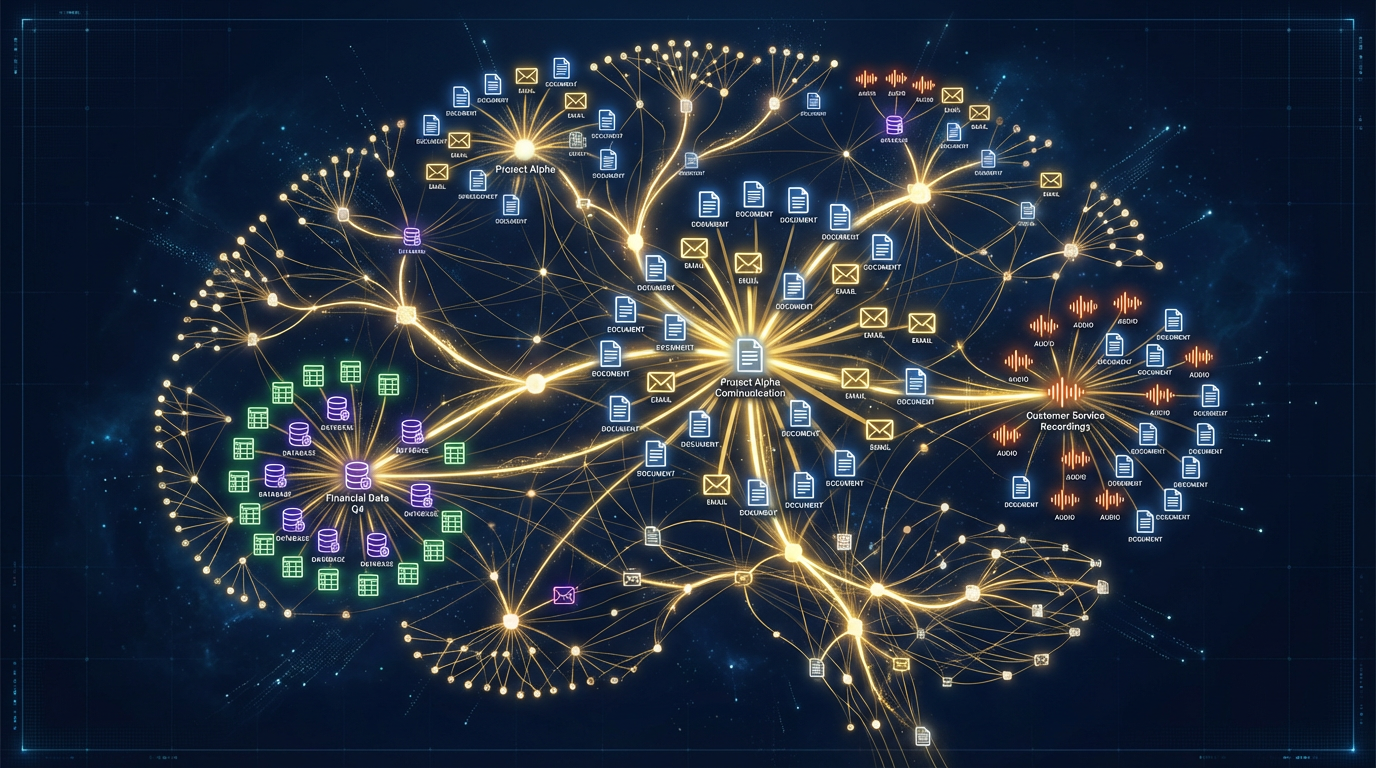
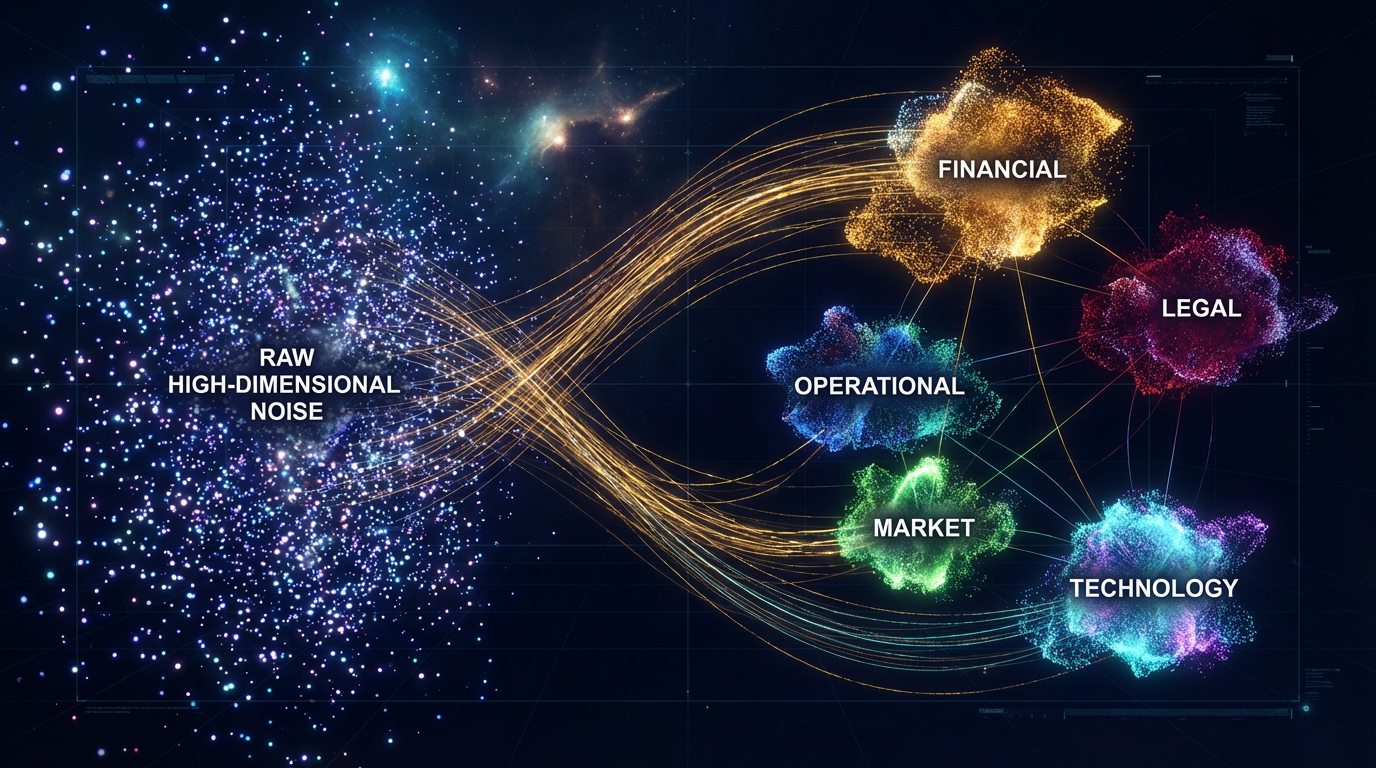
Cross-source relationship map — how CortexDD connects findings across the data room and live operating systems